Au secours tout a brûlé et on a pas de PRA
2020 c’était une plaie comme année, et je m’étais dit que 2021 ça ne pourrait pas être pire. Bienvenue dans ce premier article de 2021.
Je sors juste d’une semaine de plan de reprise d’activité, et à la vue de tout ce que j’ai traversé et lu sur le sujet, je me suis dit qu’un retour d’expérience serait intéressant.
[cyklodev_summary]
La catastrophe
Vous n’êtes sans doute pas passé à coté de cet incident industriel qu’a été l’incendie du data center d’OVH à Strasbourg. C’est le genre de choses qui parait improbable, mais s’il y a une chance même infime qu’un évènement arrive, alors il arrivera.
Donc voila le bâtiment est en feu, les serveurs/services sont sous les flammes au moment de commencer cette journée du 10 mars 2021. Mais je ne le sais pas encore, tout ce que je vois c’est le sapin de noël dans le monitoring.
⏰ 7:30 : monitoring au rouge à l’embauche
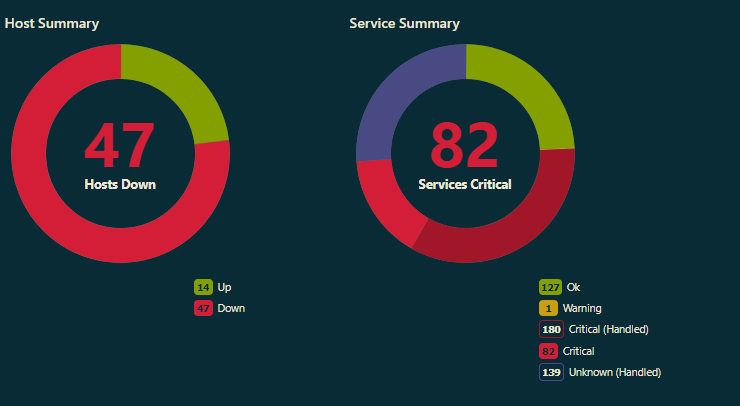
Rien qu’en voyant le résumé dans l’interface d’Icinga, je sais que la journée va être compliquée. En regardant de plus prêt quelles sondes sont au rouge, j’isole rapidement que c’est à Strasbourg que l’incident a lieu. C’était déjà arrivé par le passé avec un hyperviseur au tas et tous nos VPS inaccessibles.
Direction le backoffice d’OVH pour créer un ticket, et là j’en vois déjà un créé par un collègue d’un autre site. Petit coup de téléphone pour se synchroniser et attendant une mise à jour du ticket, quand 5 minutes plus tard il m’envoie un article des DNA où je vois cette image.
⏰ 7:50 : j’apprends que le data center brûle

En voyant cette image, je sais que tout est déjà joué, ça va être très très très difficile mais peut être pas pour tout le monde.
Le bâtiment embrasé ne fait aucun doute, si on récupère quelque chose ça ne sera pas disponible avec plusieurs jours, voir semaines.
Les conséquences
Dans ce data center, nous avions 4 VPS:
- 2 VPS pour les applications métiers avec des stacks complexes (prod/preprod)
- 2 VPS en mode plesk pour l’hébergement de sites web (prospections & shop & vitrines ).
Autant dire qu’une grande partie de la boite est à l’arrêt ou très fortement perturbée:
- le bureau d’étude ne peut plus récupérer les nouveaux projets, ni valider ceux qui étaient en cours
- la partie commerciale ne rentre plus rien via les sites web
- plus aucune commande sur la boutique en ligne
Face à de tels impacts, et après un rapide état des lieux des services touchés il est temps de vérifier l’état des sauvegardes.
Les sauvegardes ?
⏰ 7:51 : direction le serveur avec les sauvegardes
Mon 1er réflexe, je me rue sur les serveurs qui hébergent les sauvegardes … et là je ne parle pas des éventuelles sauvegardes que OVH détient, mais plus de ce que j’ai mis en place pour créer mes propres sauvegardes. On y reviendra plus bas…
C’est bon j’ai des sauvegardes du 9 à 2:30 du matin !!! Mais en fait, pas de chance, le flux de sauvegarde se synchronise à 2:30 et le monitoring m’indique que le data center a coupé à 2:14 ….
Damn , il me manquera une journée de données, mais bon j’ai des sauvegardes : configuration des serveurs, home des users et dump des bases de données pour les serveurs métiers, home des users et dump des bases pour les sites web.
Avec toutes ces infos en main, je suis en mesure de donner le choix suivant à la direction :
- on attend des informations d’OVH pour avec une date de remise en service
- on lance le PRA (plan de reprise d’activité) de suite
Clairement, vu l’ampleur de l’accident, j’ai tout de suite ma préférence pour lancer le PRA sans attendre car nous avons des sauvegardes.
PRA – DRP : le moment de vérité

On rentre maintenant dans le merveilleux monde du PRA ou DRP (Disaster Recovery Plan).
A la base ce n’est pas de la technique mais plus du process, et j’avoue que tout ce qui est process je n’en fait pas sur ce blog car ce n’est pas un sujet ici.
Donc le PRA est censé être un document qui formalise la procédure à adopter en cas d’incident majeur mettant en péril une entreprise. Clairement, dans notre entreprise on n’en a pas, et c’est une erreur. Mais la manière que j’ai eu de construire notre infrastructure va très vite s’avérer payante même si c’est un plus long à mettre en place.
J’ai une idée claire sur comment je dois le dérouler et je définis la priorité de remise en service si on me donne un go pour le lancer:
- la production pour les applications métiers
- la boutique en ligne
- la préproduction des applications métiers
- la remise en place du CD (Continuous Delivery)
- la prospection
- tout le reste
Le plus gros impact c’est la prod, je table sur la possibilité d’une date de remise en service de la prod au pire pour le lendemain matin, au mieux pour le soir même si on me donne le go pour prendre un nouveau serveur.
Dans ma tête tout est déjà clair, mais le fait de le coucher sur le papier (enfin sur le chat) est bénéfique , elle permet à la direction d’avoir de la visibilité et de pouvoir prendre une décision en connaissance de cause. Ça permet aussi de tenir informé l’équipe de l’état des services qu’ils utilisent habituellement.
⏰ 8:30 : je fais remonter l’information et le déroulement du PRA à la direction.
⏰ 9h05 : la décision tombe, j’ai le go pour lancer le PRA.
Je pense que c’est dans ce moment précis que le destin de beaucoup d’entreprises a basculé.
✅ Si les ops étaient préparés, le plan de reprise peut être déroulé, la direction sera confiante, et elle pourra communiquer sereinement.
❌ Si personne dans l’entreprise n’a prévu quelque chose, les moments qui vont arrivés seront difficiles et stressant car ni la direction ni les ops n’auront de visibilité, et ils seront en position défensive et attentiste.
Déroulement du PRA
Je vais maintenant vous décrire les étapes de la réouverture de la production pour vous donner une idée de comment tout est reparti. Toutes les autres phases du PRA suivirent le même déroulement.
Commande du serveur
Ma 1ere idée est de m’affranchir d’OVH et surtout des VPS sur lesquels les performances n’étaient pas forcement au rendez vous et sur lesquels on a déjà eu du downtime plusieurs fois.
Direction donc notre autre provider Scaleway (anciennement Online, et encore plus anciennement Dedibox), l’idée étant surtout de passer sur du physique mais également chez un hébergeur avec qui je travaille depuis plus de 10 ans et avec qui je dépasse allègrement les 1000 jours d’uptime des OS.
⏰ 9:05 : le serveur est commandé
Installation du serveur
⏰ 9:10 : le serveur est livré dans notre backoffice
L’installation de l’OS débute et, c’est aussi un sujet du moment, sur une CentOS 7 car RedHat a refroidi mes attentes sur la version majeur 8 avec l’arrivée de CentOS Stream. Avec la 7 je tiendrai tranquillement jusqu’à la fin du support en 2024.
Après avoir configuré le RAID et attendu que le ssh soit disponible, je prépare les sauvegardes que j’ai sous la main et je vérifie l’état de mes outils de déploiement.
⏰ 10:00 : accès ssh sur le nouveau serveur
Déploiement sur le serveur
Là aussi il peut y avoir un grand écueil. Une stack métier peut être complexe même bâtie sur de l’opensource. Dans notre cas on cumule les technos suivantes :
- Nginx
- Node
- Php
- Java
- Maven
- MySQL
- Mongo
- Runner Gitlab
Sans compter toute la partie serveur :
- firewall
- interconnexion de serveurs
- path spécifiques
- plusieurs « service » user
- configuration sudo
- droits spécifiques
Remonter tout ceci à la main à partir des documents d’archi aurait certainement pris des jours. Mais il y a une parade à tout ceci : le IAC (Infra As Code) qui est intimement lié au IaaS (Infrastructure as a Service). L’idée étant que toute la procédure d’installation doit être décrite en tant que code, et donc automatisée et par extension versionnée.
Ces outils sont légions: Puppet, Chef, Ansible , etc …
Si vous lisez ce blog, vous connaissez sûrement les raisons de mon choix et ma préférence pour Ansible. J’avais même fait une présentation en interne à mes collègues pour leur vanter les mérites d’avoir une infrastructure construite la dessus il y a plus d’un an.
Un échange de clé SSH, plus tard et le déploiement du serveur commence…
⏰ 10:02 : lancement du playbook
Loin d’être inquiet j’en profite pour aller chercher un café. A mon retour le déploiement est toujours en cours mais se bloque peu de temps après. J’avais fait l’erreur de faire un wget sur un miroir pour récupérer maven, et le mirroir n’était plus accessible. Je corrige le lien et je continue de dérouler le déploiement.
Au total, 21 minutes de déploiement pour toute la stack.
⏰ 10:33 : fin du playbook
Il reste à restaurer les sauvegardes.
Les sauvegardes
Le dénouement est ici, car oui quand on est adminsys on se doit de respecter la sacrosainte règle 3-2-1 et cela quoi qu’il en coûte.
- 3 sauvegardes
- 2 types de supports différents
- 1 site externe
Ça parait lourd à gérer mais finalement le coût en vaut la chandelle. Alors vous pouvez me dire ça coûte cher, et effectivement ça peut le devenir, tout dépend des services/données et de leur valeur. Mais c’est prendre le problème du mauvais coté. Il est préférable de regarder ça dans le sens inverse: quelle est le manque à gagner en cas de perte de ces services/données.
Dans notre cas, notre premier pare-feu c’était d’avoir une machine de preprod au même endroit que la prod. Pas de bol , elle est également touchée. J’ai en ma possession les sauvegardes de la veille (9/03 à 2:30) chez un autre provider :
- une archive tar.gz de tous les fichiers système importants (iptables, hosts, config nginx, sondes icinga, etc…)
- une archive tar.gz de toutes les homes des users
- un dump mongo
- un dump mysql
Voila ce qui s’appelle une sauvegarde à froid et cela disponible dans un autre data center, mise a jour toutes les nuits, ainsi que sur un troisième site en local si vraiment vraiment tout internet casse.
Il ne reste plus qu’a faire un rsync vers le nouveau serveur et à décompresser le tout dans les bons répertoires, et de faire un import des bases de données et des collections.
Redémarrage
Après un redémarrage à la main des services, plusieurs vérifications coté système que tout fonctionne proprement, on y est enfin.
⏰ 12:35 : la production est restaurée
Pour assurer nos arrières, on lance une campagne de tests des fonctionnalités avec les personnes concernées de l’équipe. Cela permettra d’ouvrir les services aux utilisateurs sans être obligé de couper si on avait raté quelque chose.
Pendant que la campagne de vérification se déroule, j’en profite pour ajouter le nouveau serveur dans le monitoring. Dans les sauvegardes, je prenais bien soin de mettre les sondes locales qui sont sur les serveurs, ce qui m’a permis de rapidement vérifier l’état du serveur et surtout des services.
Avec l’ensemble des sondes qui sont au vert, je confirme la vision des dev sur l’état des services. On peut réouvrir les services de prod.
⏰ 16:30 : tout est au vert dans le monitoring, la demande de migration des dns est faite
Enseignements

Les sauvegardes
Il n’y a pas de secret, faites des sauvegardes, toujours et tout le temps. Des sauvegardes locales et distantes et encore re distantes. L’idée est d’avoir la possibilité de récuperer des sauvegardes et cela même si 2 sites brulent.
Et franchement, ce n’est pas compliqué, on parle de faire un script avec un tar pour compresser et un rsync pour le mettre ailleurs. Même des débutants sont capables de mettre ça en place, c’est d’ailleurs un très bon exercice pour débuter.
Il faut aussi penser à tout sauvegarder : les home des users, les bases de données mais aussi et surtout les configurations de serveurs. Rien n’est pire que d’avoir data+db mais de ne plus avoir les fichiers de configuration. Ça génère du boulot inutile.
Avoir des sauvegardes n’est pas suffisant, il faut aussi vérifier qu’elles soient intègres. Pour ça, l’environnement de preprod est super important, car ça permet de tester la restauration des sauvegardes de prod et donc leur intégrité.
Infra As Code
Déployer des stacks complexes, ou même simples, doit pouvoir se faire rapidement. S’appuyer sur des outils de déploiement automatisé permet de s’affranchir des petits oublis, et d’être confiant sur une configuration d’OS répétable.
L’autre avantage c’est de pouvoir faire une preprod ou une dev avec la même structure en changeant quelques variables. Ça uniformise énormément les configurations, et ça réduit le gap et les éventuelles erreurs de déploiement entre environnements.
Le monitoring
L’autre point essentiel, c’est de monitorer son infrastructure et pas seulement le triptyque cpu/ram/disk. Il faut aussi monitorer les services, les scenarios applicatifs. Alors c’est sur ,ça ne se fait pas en une journée, ni une semaine.
C’est un travail de longue haleine, et surtout quand on trouve un crash qui n’a pas passé une sonde au rouge, il faut immédiatement faire une sonde pour détecter ce comportement. Ainsi au fur et à mesure, la couverture de l’infra va s’améliorer.
Il y a autre chose qui m’a rendu particulièrement serein au moment où j’ai compris que le PRA allait débuter. J’ai mis en place des sondes qui vérifient que les backups sont bien générés et qu’ils sont bien envoyés sur le 2ème et le 3ème site. Avec cela, chaque jour, je sais si je suis capable de repartir de zéro le lendemain.
PRA
Alors oui, on avait pas de plan de reprise d’activité et c’est bien sûr à éviter. Nul doute que quand tout sera calmé je vais m’y mettre.
Mais sans PRA, on a pu repartir en 3h30 ce qui n’est pas mauvais à la vue de tous les sites ou applications qui ne sont pas encore répartis.
Les quelques pratiques que je vous ai détaillées sont des bases solides pour avoir une architecture résiliente et peuvent sans aucun doute être la base de votre PRA.
Épilogue
A l’heure où j’ai écrit cet article, OVH commence à redémarrer les premiers serveurs, mais pour nous cette histoire est déjà loin derrière nous.
Alors j’ai lu énormément de commentaires énervés sur twitter en pointant les manquements de OVH. Mais très franchement c’est se voiler la face.
OVH n’a pas l’obligation légale de faire de sauvegardes à votre place (sauf si vous y souscrivez), et encore moins de mettre un PRA en place pour vous. Le PRA est de la responsabilité du DSI et du dirigeant de l’entreprise, et pas uniquement pour un PRA informatique.
C’est même plutôt l’inverse, c’est vos clients qui peuvent se retourner contre vous, car eux à l’inverse, attendent de vous que vous sécurisiez leur données.
Voila une preuve par l’exemple que sans PRA, mais en ayant construit une infra de manière cohérente, en respectant les règles simples, on peut aisément se prémunir des conséquences d’un incident majeur sur son infrastructure.


